深入浅出 Rust笔记 Series 2
系列导航
这是我在阅读范长春的《深入浅出 Rust》时做的笔记,绝大部分内容源自此书,另有小部分内容源自 Rust 圣经。这两份资料是我入门 Rust 的主要材料。
第二部分 内存安全
Rust 希望通过语言的机制和编译器的功能,把程序员易犯错、不易检查的问题解决在编译期,避免运行时的内存错误。这一部分主要探讨 Rust 是如何达到内存安全特性的。
chap 10 内存管理基础
-
segmentation fault 形成:进程空间中的每个段通过硬件 MMU 映射到真正的物理空间;在这个映射过程中可以给不同的段设置不同的访问权限,比如代码段就是只能读不能写;进程在执行过程中,如果违反了这些权限,CPU 会直接产生一个硬件异常;硬件异常会被操作系统内核处理,一般内核会向对应的进程发送一条信号;如果没有实现自己特殊的信号处理函数,默认情况下,这个进程会直接非正常退出;如果操作系统打开了 core dump 功能,在进程退出的时候操作系统会把它当时的内存状态、寄存器状态以及各种相关信息保存到一个文件中,供用户以后调试使用。
-
非内存安全的情况
- 空指针:解引用空指针是不安全的。这块地址空间一般是受保护的,对空指针解引用在大部分平台上会产生 segfault。
- 野指针:指的是未初始化的指针。它的值取决于它这个位置以前遗留下来的是什么值。所以它可能指向任意一个地方。对它解引用,可能会造成 segfault,也可能不会,纯粹凭运气。但无论如何,这个行为都不会是预期内的行为,是一定会产生 bug 的。
- 悬空指针:指的是内存空间在被释放了之后,继续使用。它跟野指针类似,同样会读写已经不属于这个指针的内容。
- 使用未初始化内存:不只是指针类型,任何一种类型不初始化就直接使用都是危险的,造成的后果完全无法预测。
- 非法释放:内存分配和释放要配对。如果对同一个指针释放两次,会制造出内存错误。如果指针并不是内存分配器返回的值,对其执行释放操作,也是危险的。
- 缓冲区溢出:指针访问越界了,结果也是类似于野指针,会读取或者修改临近内存空间的值,造成危险。
- 执行非法函数指针:如果一个函数指针不是准确地指向一个函数地址,那么调用这个函数指针会导致一段随机数据被当成指令来执行,是非常危险的。
- 数据竞争:在有并发的场景下,针对同一块内存同时读写,且没有同步措施。
-
一些内存错误是不算在“内存安全”范畴内的,比如内存泄漏以及内存耗尽。另外,panic 也不属于内存安全相关的问题。
-
panic 和 core dump 之间有重要区别。panic 是发生不可恢复错误后,程序主动执行的一种错误处理机制;而 core dump 则是程序失控之后,触发了操作系统的保护机制而被动退出的。发生 panic 的时候,此处就是确定性的第一现场,我们可以根据 call stack 信息很快找到事发地点,然后修复。panic 是防止更严重内存安全错误的重要机制。
chap 11 所有权和移动语义
11.1 所有权
-
“所有权”代表着以下意义:
- 每个值在 Rust 中都有一个变量来管理它,这个变量就是这个值、这块内存的所有者;
- 每个值在一个时间点上只有一个管理者;
- 当变量所在的作用域结束的时候,变量以及它代表的值将会被销毁。
-
在 Rust 中不可以做“赋值运算符重载”,若需要“深复制”,必须手工调用 clone 方法。这个 clone 方法来自于 std::clone::Clone 这个 trait。clone 方法里面的行为是可以自定义的。
11.2 移动语义
-
一个变量可以把它拥有的值转移给另外一个变量,称为“所有权转移”。赋值语句、函数调用、函数返回等,都有可能导致所有权转移。
-
Rust 中的变量绑定操作,默认是 move 语义,执行了新的变量绑定后,原来的变量就不能再被使用。
-
“语义”不代表最终的执行效率。“语义”只是规定了什么样的代码是编译器可以接受的,以及它执行后的效果可以用怎样的思维模型去理解。编译器有权在不改变语义的情况下做任何有利于执行效率的优化。语义和优化是两个阶段的事情。
1
2
3
4
5
6
7
8
9
10
11
12
13fn create() -> BigObject {
let local = …;
return local;
}
let v = create();
// 完全可能被优化为类似如下的效果:
fn create(p: &mut BigObject) {
ptr::write(p, …);
}
let mut v: BigObject = uninitialized();
create(&mut v);编译器可以提前在当前调用栈中把大对象的空间分配好,然后把这个对象的指针传递给子函数,由子函数执行这个变量的初始化。这样就避免了大对象的复制工作,参数传递只是一个指针而已。这么做是完全满足移动语义要求的,而且编译器还有权利做更多类似的优化。
11.3 复制语义
-
对于一些简单类型,比如整数、bool,在赋值的时候默认采用复制操作
1
2
3
4
5fn main() {
let v1 : isize = 0;
let v2 = v1;
println!("{}", v1);
}在 Rust 中有一部分“特殊照顾”的类型,其变量绑定操作是 copy 语义。所谓的 copy 语义,是指在执行变量绑定操作的时候,v2 是对 v1 所属数据的一份复制。v1 所管理的这块内存依然存在,并未失效,而 v2 是新开辟了一块内存,它的内容是从 v1 管理的内存中复制而来的。和手动调用 clone 方法效果一样,
let v2=v1; 等效于let v2 = v1.clone();。 -
copy 语义与 move 语义:这两个操作本身是一样的,都是简单的内存复制,区别在于复制完
以后,原先那个变量的生命周期是否结束。 -
在普通变量绑定、函数传参、模式匹配等场景下,凡是实现了 std::marker::Copy trait 的类型,都会执行 copy 语义。基本类型,比如数字、字符、bool 等,都实现了 Copy trait,因此具备 copy 语义。
-
对于自定义类型,默认是没有实现 Copy trait 的,可以手动添上。Copy 继承了 Clone,要实现 Copy trait 必须同时实现 Clone trait。只要一个类型的所有成员都具有 Clone trait,就可以使用
#[derive(Copy, Clone)]来让编译器实现 Clone trait 了。
11.4 Box 类型
- Box 类型是 Rust 中一种常用的指针类型。Box 代表“拥有所有权的指针”,类似于 C++ 里面的 unique_ptr(严格来说,unique_ptr
更像 Option<Box >) - Box 类型永远执行的是 move 语义,不能是 copy 语义。Rust 中的 copy 语义就是浅复制。对于 Box 这样的类型而言,浅复制必然会造成二次释放问题。
- 它包裹的值会被强制分配在堆上
-
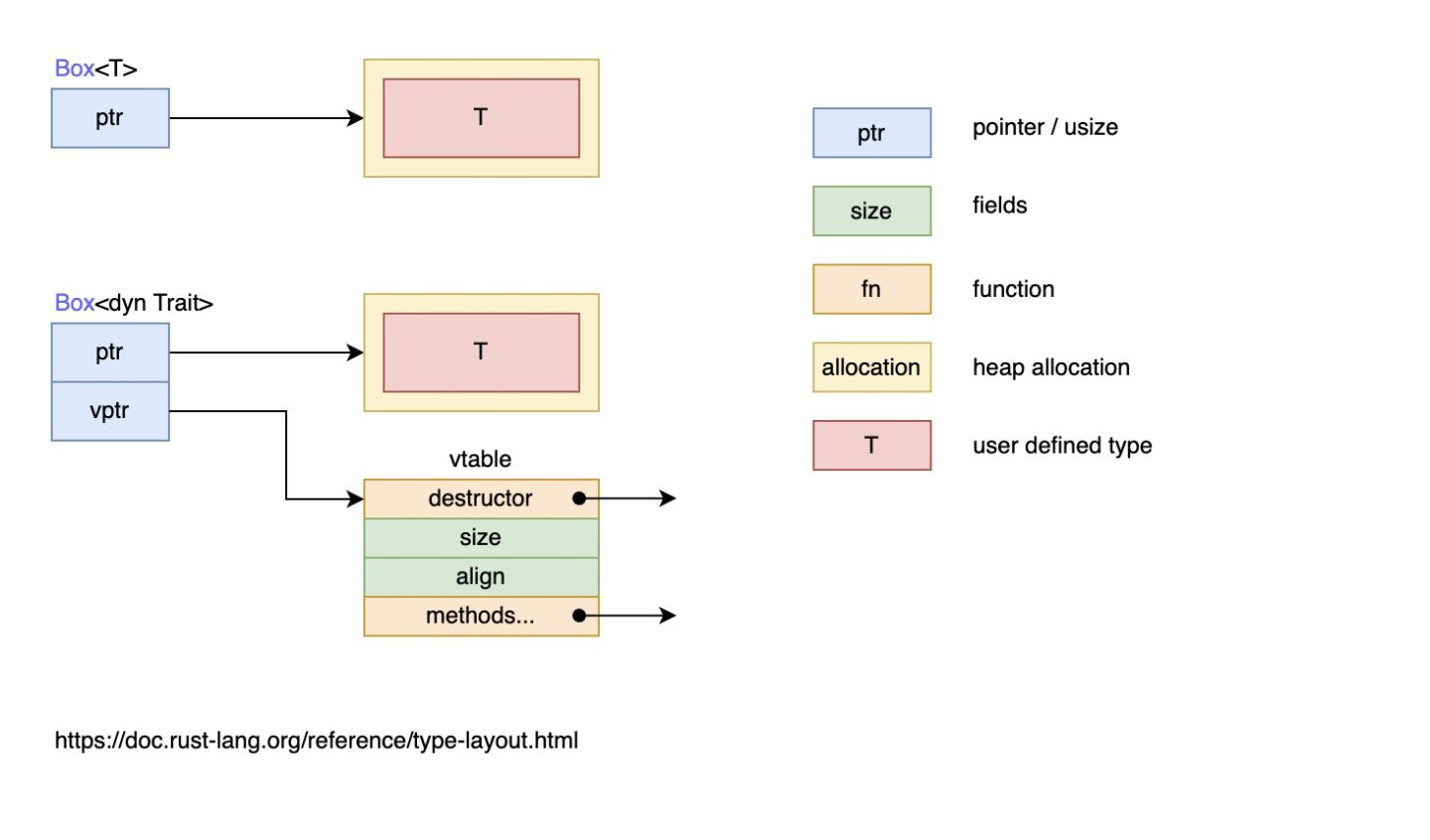
- 由于
Box 是简单的封装,除了将值存储在堆上外,并没有其它性能上的损耗。而性能和功能往往是鱼和熊掌,因此Box 相比其它智能指针,功能较为单一,可以在以下场景中使用它:- 特意的将数据分配在堆上
- 数据较大时,又不想在转移所有权时进行数据拷贝:当栈上数据转移所有权时,实际上是把数据拷贝了一份,最终新旧变量各自拥有不同的数据,因此所有权并未转移。而堆上则不然,底层数据并不会被拷贝,转移所有权仅仅是复制一份栈中的指针,再将新的指针赋予新的变量,然后让拥有旧指针的变量失效,最终完成了所有权的转移。
- 类型的大小在编译期无法确定,但是我们又需要固定大小的类型时
- 特征对象,用于说明对象实现了一个特征,而不是某个特定的类型
- Box::leak 使用场景:需要一个在运行期初始化的值,但是可以全局有效,也就是和整个程序活得一样久
11.5 Clone VS Copy
-
std::marker::Copy:如果一个类型 impl 了 Copy trait,意味着任何时候都可以通过简单的内存复制(在 C 语言里按字节复制 memcpy)实现该类型的复制,并且不会产生任何内存安全问题。一旦一个类型实现了 Copy trait,那么它在变量绑定、函数参数传递、函数返回值传递等场景下,都是 copy 语义,而不再是默认的 move 语义。
- std::marker 模块里面所有的 trait 都是特殊的 trait。目前稳定的有四个,它们是 Copy、Send、Sized、Sync。它们的特殊之处在于:它们是跟编译器密切绑定的,impl 这些 trait 对编译器的行为有重要影响。在编译器眼里,它们与其他的 trait 不一样。这几个 trait 内部都没有方法,它们的唯一任务是给类型打一个“标记”,表明它符合某种约定——这些约定会影响编译器的静态检查以及代码生成。
-
Copy 的实现条件
- 对于自定义类型,只有所有成员都实现了 Copy trait,这个类型才有资格实现 Copy trait。struct 和 enum 类型不会自动实现 Copy trait,只有当 struct 和 enum 内部的每个元素都是 Copy 类型时,编译器才允许针对此类型实现 Copy trait。而对于元组 tuple 类型,如果它的每一个元素都是 Copy 类型,那么这个 tuple 也是 Copy 类型。
- 常见的数字类型、bool 类型、共享借用指针&,都是具有 Copy 属性的类型。
- Box、Vec、可写借用指针&mut 等类型都是不具备 Copy 属性的类型。
- 对于数组类型,如果它内部的元素类型是 Copy,那么这个数组也是 Copy 类型。
-
std::clone::Clone:clone 方法一般用于“基于语义的复制”操作。所以,它做什么事情,跟具
体类型的作用息息相关。比如,对于 Box 类型,clone 执行的是“深复制”;而对于 Rc 类型,clone 做的事情就是把引用计数值加 1。对于实现了 copy 的类型,它的 clone 方法应该跟 copy 语义相容,等同于按字节复制。1
2
3
4
5
6pub trait Clone : Sized {
fn clone(&self) -> Self;
fn clone_from(&mut self, source: &Self) {
*self = source.clone()
}
}有两个关联方法,分别是 clone_from 和 clone,clone_from 是有默认实现的,依赖于 clone 方法的实现。clone 方法没有默认实现,需要手动实现。
-
#[derive(Clone)] 让编译器自动生成那些重复的代码。编译器自动生成的 clone 方法非常机械,就是依次调用每个成员的 clone 方法。
-
-
总结
- Copy 内部没有方法,Clone 内部有两个方法(clone、clone_from)
- Copy trait 是给编译器用的,告诉编译器这个类型默认采用 copy 语义而不是 move 语义。Clone trait 是给程序员用的,必须手动调用 clone 方法它才能发挥作用。
- Copy trait 不是想实现就能实现的,它对类型是有要求的,有些类型(Box
)不可能 impl Copy。而 Clone trait 则没有什么前提条件,任何类型都可以实现(unsized 类型除外,因为无法使用 unsized 类型作为返回值)。 - Copy trait 规定了这个类型在执行变量绑定、函数参数传递、函数返回等场景下的操作方式。即这个类型在这种场景下,必然执行的是“简单内存复制”操作,这是由编译器保证的,程序员无法控制。Clone trait 里面的 clone 方法究竟会执行什么操作,则是取决于程序员自己写的逻辑。一般情况下,clone 方法应该执行一个“深复制”操作,但这不是强制性的
- Rust 规定了在 T:Copy 的情况下 Clone trait 代表的含义。即:当某变量 t:T 符合 T:Copy 时,它调用 t.clone() 方法的含义必须等同于“简单内存复制”。也就是说,
t.clone() 的行为必须等同于let x = std::ptr::read(&t); ,也等同于let x = t; 。
析构
-
在 Rust 中编写“析构函数”的办法是 impl std::ops::Drop。Drop trait 的定义如下:
1
2
3trait Drop {
fn drop(&mut self);
} -
主动析构:用户主动调用析构函数是非法的。需调用标准库中的 std::mem::drop()
-
std::mem::drop() 实现
1
2#[inline]
pub fn drop<T>(_x: T) { }- drop 函数不需要任何的函数体,只需要参数为“值传递”即可。将对象的所有权移入函数中,什么都不用做,编译器就会自动释放掉这个对象了。
- 因为这个 drop 函数的关键在于使用 move 语义把参数传进来,使得变量的所有权从调用方移动到 drop 函数体内,参数类型一定要是 T,而不是&T 或者其他引用类型。函数体本身其实根本不重要,重要的是把变量的所有权 move 进入这个函数体中,函数调用结束的时候该变量的生命周期结束,变量的析构函数会自动调用,管理的内存空间也会自然释放。这个过程完全符合前面讲的生命周期、move 语义,无须编译器做特殊处理。
- 因此,对于 Copy 类型的变量,对它调用 std::mem::drop() 是没有意义的。因为 Copy 类型在函数参数传递的时候执行的是复制语义,原来的那个变量依然存在,传入函数中的只是一个复制品,因此原变量的生命周期不会受到影响。
-
-
变量遮蔽(Shadowing)不会导致变量生命周期提前结束,它不等同于 drop。
-
注意:用下划线来绑定一个变量,那么这个变量会当场执行析构,而不是等到当前语句块结束的时候再执行。下划线是特殊符号,不是普通标识符。
-
std::mem::drop()函数和 std::ops::Drop::drop()方法的区别
- std::mem::drop()函数是一个独立的函数,不是某个类型的成员方法,它由程序员主动调用,作用是使变量的生命周期提前结束;std::ops::Drop::drop()方法是一个 trait 中定义的方法,当变量的生命周期结束的时候,编译器会自动调用,手动调用是不允许的。
- std::mem::drop
(_x:T)的参数类型是 T,采用的是 move 语义;std::ops::Drop::drop(&mut self)的参数类型是&mut Self,采用的是可变借用。在析构函数调用过程中,程序员还有机会读取或者修改此对象的属性。
chap 12 借用和生命周期
-
生命周期简而言之就是引用的有效作用域。生命周期符号使用单引号开头,后面跟一个合法的名字。生命周期标记和泛型类型参数是一样的,都需要先声明后使用。
1
2
3fn test<'a>(arg: &'a T) -> &'a i32 {
&arg.member
} -
一个生命周期标注,它自身并不具有什么意义,因为生命周期的作用就是告诉编译器多个引用之间的关系。例如,有一个函数,它的第一个参数
first 是一个指向i32 类型的引用,具有生命周期'a,该函数还有另一个参数second,它也是指向i32 类型的引用,并且同样具有生命周期'a。此处生命周期标注仅仅说明,这两个参数first 和second 至少活得和’a 一样久,至于到底活多久或者哪个活得更久都无法得知。 -
借用指针类型都有一个生命周期泛型参数,它们的完整写法应该是&'a T、&'a mut T,只不过在做局部变量的时候,生命周期参数是可以省略的。
-
生命周期之间有重要的包含关系。如果生命周期’a 比’b 更长或相等,则记为’a: 'b,意思是’a 至少不会比’b 短。'static 是一个特殊的生命周期,它代表的是这个程序从开始到结束的整个阶段,所以它比其他任何生命周期都长。这意味着,任意一个生命周期’a 都满足’static: 'a。
-
Rust 的引用类型是支持“协变”的。在编译器眼里,生命周期就是一个区间,生命周期参数就是一个普通的泛型参数,它可以被特化为某个具体的生命周期。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15fn select<'a>(arg1: &'a i32, arg2: &'a i32) -> &'a i32 {
if *arg1 > *arg2 {
arg1
}
else {
arg2
}
}
fn main() {
let x = 1;
let y = 2;
let selected = select(&x, &y);
println!("{}", selected);
}- select 函数引入了一个生命周期标记,两个参数以及返回值都是用的这个生命周期标记。在调用的时候,传递的实参其实是具备不同的生命周期的。x 的生命周期明显大于 y 的生命周期,&x 可存活的范围要大于&y 可存活的范围,将它们的实际生命周期分别记录为’x 和’y。select 函数的形式参数要求的是同样的生命周期,而实际参数是两个不同生命周期的引用,这个类型之所以可以匹配成功,就是因为生命周期的协变特性。编译器可以把&x 和&y 的生命周期都缩小到某个生命周期’a 以内,且满足’x:'a,'y:'a。返回的 selected 变量具备’a 生命周期,也并没有超过’x 和’y 的范围。所以,最终的生命周期检查可以通过。
-
编译器使用三条消除规则来确定哪些场景不需要显式地去标注生命周期。其中第一条规则应用在输入生命周期上,第二、三条应用在输出生命周期上。若编译器发现三条规则都不适用时,就会报错,提示你需要手动标注生命周期。
- 每一个引用参数都会获得独自的生命周期例如一个引用参数的函数就有一个生命周期标注:
fn foo<'a>(x: &'a i32),两个引用参数的有两个生命周期标注:fn foo<'a, 'b>(x: &'a i32, y: &'b i32), 依此类推。 - 若只有一个输入生命周期(函数参数中只有一个引用类型),那么该生命周期会被赋给所有的输出生命周期,也就是所有返回值的生命周期都等于该输入生命周期例如函数
fn foo(x: &i32) -> &i32,x 参数的生命周期会被自动赋给返回值&i32,因此该函数等同于fn foo<'a>(x: &'a i32) -> &'a i32 - 若存在多个输入生命周期,且其中一个是
&self 或 &mut self,则 &self 的生命周期被赋给所有的输出生命周期拥有&self 形式的参数,说明该函数是一个方法,该规则让方法的使用便利度大幅提升。
- 每一个引用参数都会获得独自的生命周期例如一个引用参数的函数就有一个生命周期标注:
chap 15 内部可变性
-
Rust 的 borrow checker 的核心思想是“共享不可变,可变不共享”。但是只有这个规则是不够的,在某些情况下,我们的确需要在存在共享的情况下可变。为了让这种情况是可控的、安全的,Rust 还设计了一种“内部可变性”(interior mutability)
-
承袭可变性:Rust 中的 mut 关键字不能在声明类型的时候使用,只能跟变量一起使用。类型本身不能规定自己是否是可变的。一个变量是否是可变的,取决于它的使用环境,而不是它的类型。可变还是不可变取决于变量的使用方式。不能在类型声明的时候指定可变性,比如在 struct 中对某部分成员使用 mut 修饰,这是不合法的。只能在变量声明的时候指定可变性。也不能针对变量的某一部分成员指定可变性,其他部分保持不变。
-
存在 &mut T 就不能存在 &T 的原因:这会引发内存安全问题。比如同时拥有 Vec 的可变引用和不可变引用,通过可变引用向该 Vec 中 push 数据,发生扩容后再去读原来的不可变引用,此时那块内存已经失效(迭代器失效)
-
内部可变性——可以通过共享指针修改它内部的值。虽然粗略一看,Cell 类型似乎违反了 Rust 的“唯一修改权”原则。可以存在多个指向 Cell 类型的不可变引用,同时还能利用不可变引用改变 Cell 内部的值。但实际上,这个类型是完全符合“内存安全”的。再想想,为什么 Rust 要尽力避免 alias 和 mutation 同时存在?因为假如同时有可变指针和不可变指针指向同一块内存,有可能出现通过一个可变指针修改内存的过程中,数据结构处于被破坏状态的情况下,被其他的指针观测到。Cell 类型是不会出现这样的情况的。因为 Cell 类型把数据包裹在内部,用户无法获得指向内部状态的指针,这意味着每次方法调用都是执行的一次完整的数据移动操作。每次方法调用之后,Cell 类型的内部都处于一个正确的状态,不可能观察到数据被破坏掉的状态。多个共享指针指向 Cell 类型的状态如下图所示,Cell 就是一个“壳”,它把数据严严实实地包裹在里面,所有的指针只能指向 Cell,不能直接指向数据。修改数据只能通过 Cell 来完成,用户无法创造一个直接指向数据的指针。
-
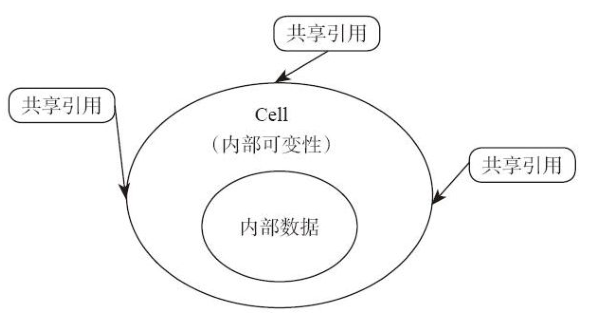
-
-
内部可变性的实现是因为 Rust 使用了
unsafe 来做到这一点,但是对于使用者来说,这些都是透明的,因为这些不安全代码都被封装到了安全的 API 中 由于Cell 类型针对的是实现了Copy 特征的值类型,因此在实际开发中,Cell 使用的并不多,因为时实际要解决的往往是可变、不可变引用共存导致的问题,此时就需要借助于RefCell 来达成目的。Cell 类型没办法制造出直接指向内部数据的指针,而 RefCell 可以;Cell 只适用于 Copy 类型,用于提供值,而 RefCell 用于提供引用。RefCell 类型放弃了编译阶段的 alias+mutation 原则,但依然会在执行阶段保证 alias+mutation 原则。 -
Rust 规则 智能指针带来的额外规则 一个数据只有一个所有者 Rc/Arc让一个数据可以拥有多个所有者要么多个不可变借用,要么一个可变借用 RefCell实现编译期可变、不可变引用共存违背规则导致编译错误 违背规则导致运行时 panic- 可以看出,
Rc/Arc 和RefCell 合在一起,解决了 Rust 中严苛的所有权和借用规则带来的某些场景下难使用的问题。但是它们并不是银弹,例如RefCell 实际上并没有解决可变引用和引用可以共存的问题,只是将报错从编译期推迟到运行时,从编译器错误变成了panic 异常
- 可以看出,
-
内部可变性小例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
pub trait Messenger {
fn send(&self, msg: String);
}
// --------------------------
// 我们的代码中的数据结构和实现
struct MsgQueue {
msg_cache: Vec<String>,
}
impl Messenger for MsgQueue {
fn send(&self, msg: String) {
self.msg_cache.push(msg)
}
}-
如上所示,外部库中定义了一个消息发送器特征
Messenger,它只有一个发送消息的功能:fn send(&self, msg: String),因为发送消息不需要修改自身,因此原作者在定义时,使用了&self 的不可变借用,这个无可厚非。要在自己的代码中使用该特征实现一个异步消息队列,出于性能的考虑,消息先写到本地缓存(内存)中,然后批量发送出去,因此在
send 方法中,需要将消息先行插入到本地缓存msg_cache 中。但是问题来了,该send 方法的签名是&self,因此上述代码会报错:
1
2
3
4
5
6
7
8error[E0596]: cannot borrow `self.msg_cache` as mutable, as it is behind a `&` reference
--> src/main.rs:11:9
|
2 | fn send(&self, msg: String);
| ----- help: consider changing that to be a mutable reference: `&mut self`
...
11 | self.msg_cache.push(msg)
| ^^^^^^^^^^^^^^^^^^ `self` is a `&` reference, so the data it refers to cannot be borrowed as mutable- 在报错的同时,编译器大聪明还善意地给出了提示:将
&self 修改为&mut self,但是。。。我们实现的特征是定义在外部库中,因此该签名根本不能修改。值此危急关头,RefCell 闪亮登场:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22use std::cell::RefCell;
pub trait Messenger {
fn send(&self, msg: String);
}
pub struct MsgQueue {
msg_cache: RefCell<Vec<String>>,
}
impl Messenger for MsgQueue {
fn send(&self, msg: String) {
self.msg_cache.borrow_mut().push(msg)
}
}
fn main() {
let mq = MsgQueue {
msg_cache: RefCell::new(Vec::new()),
};
mq.send("hello, world".to_string());
}- 这个 MQ 功能很弱,但是并不妨碍我们演示内部可变性的核心用法:通过包裹一层
RefCell,成功的让&self 中的msg_cache 成为一个可变值,然后实现对其的修改。
-
-
性能上看,
RefCell 由于是非线程安全的,因此无需保证原子性,性能虽然有一点损耗(需要维护一个借用计数器),但是依然非常好,而Cell 则完全不存在任何额外的性能损耗。- RefCell 原理:RefCell 内部有一个“借用计数器”,调用 borrow 方法的时候,计数器里面的“共享引用计数”值就加 1。当这个 borrow 结束的时候,会将这个值自动减 1(如下图所示)。同样,borrow_mut 方法被调用的时候,它就记录一下当前存在“可变引用”。如果“共享引用”和“可变引用”同时出现了,就会报错。
-
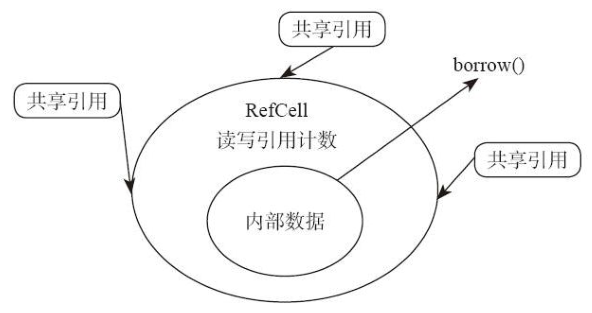
-
Cell::get_mut(&mut self) 可以获取 &mut T,由此可以改变 Cell 内部包裹的值;这个方法和Cell::set(&self, , val: T) 有何区别? 回答:区别在于 self 的类型,前者是可变引用,后者是不可变引用。在能获取到可变引用的情况下修改内部的数据是理所当然的,但正是在不可变引用下还能修改体现了内部可变性。 -
Cell 和 RefCell 部分 API
1
2
3
4
5
6
7
8
9
10
11impl<T> Cell<T> {
pub fn get_mut(&mut self) -> &mut T { }
pub fn set(&self, val: T) { }
pub fn swap(&self, other: &Self) { }
pub fn replace(&self, val: T) -> T { }
pub fn into_inner(self) -> T { }
}
impl<T:Copy> Cell<T> {
pub fn get(&self) -> T { }
}1
2
3
4
5
6
7impl<T: ?Sized> RefCell<T> {
pub fn borrow(&self) -> Ref<T> { }
pub fn try_borrow(&self) -> Result<Ref<T>, BorrowError> { }
pub fn borrow_mut(&self) -> RefMut<T> { }
pub fn try_borrow_mut(&self) -> Result<RefMut<T>, BorrowMutError> { }
pub fn get_mut(&mut self) -> &mut T { }
}
chap 16 解引用(智能指针)
-
解引用操作可以被自定义。方法是实现标准库中的 std::ops::Deref 或者 std::ops::DerefMut 这两个 trait。
1
2
3
4
5
6
7
8pub trait Deref {
type Target: ?Sized;
fn deref(&self) -> &Self::Target;
}
pub trait DerefMut: Deref {
fn deref_mut(&mut self) -> &mut Self::Target;
} -
Rust 提供的“自动解引用”机制,是在某些场景下“隐式地”“自动地”做了一些事情:Rust 编译器做了隐式的 deref 调用,当它找不到这个成员方法的时候,会自动尝试使用 deref 方法后再找该方法,一直循环下去。一般情况下,在函数调用的时候,编译器会帮我们尝试自动解引用。但在某些情况下,编译器不会为我们自动插入自动解引用的代码。
-
自动 deref 的规则是,如果类型 T 可以解引用为 U,即
T:Deref<U>,则&T 可以转为&U。让智能指针透明。这就是自动 Deref 的意义。 -
std::rc::Rc
:Rc 指针及其 clone 出的指针对它指向的内部数据只有读功能,和共享引用&一致,因此,它是安全的。区别在于,共享引用对数据完全没有所有权,不负责内存的释放,Rc 指针会在引用计数值减到 0 的时候释放内存。Rust 里面的 Rc<T>类型类似于 C++ 里面的 shared_ptr<const T>类型,且强制不可为空。 - Rc 实现了 Clone 和 Drop 这两个 trait。在 clone 方法中,它没有对它内部的数据实行深复制,而是将强引用计数值加 1;在 drop 方法中,也没有直接把内部数据释放掉,而是将强引用计数值减 1,当强引用计数值减到 0 的时候,才会析构掉共享的那块数据。当弱引用计数值也减为 0 的时候,才说明没有任何 Rc/Weak 指针指向这块内存,它占用的内存才会被彻底释放。
- 内部的引用计数是 Cell
类型
-
std::borrow::Cow:当它只需要对所指向的数据进行只读访问的时候,它就只是一个借用指针;当它需要写数据功能时,它会先分配内存,执行复制操作,再对自己拥有所有权的内存进行写入操作。
-
零开销原则:
C++ implementations obey the zero-overhead principle:What you don’t use,you don’t pay for. And further:What you do use,you couldn’t hand code any better. ——Stroustrup
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!