Rust Analyzer 的 IDE 功能实现 Series 1 —— LSP
前言
最近给 Rust Analyzer(RA) 贡献了一些 PR,在这过程中对于它的 IDE 功能实现挺感兴趣的,于是有了新年的这第一篇博客,记录一下我在探索 Rust Analyzer 的 IDE 功能实现的过程。首先想先从 LSP(Language Server Protocol) 在 Rust Analyzer 中的实现开始,后面可能会介绍一些其他内容,比如 RA 服务端的 AST 解析、智能 assist 和 diagnostic quickfix 实现、HIR lowering … (有可能会鸽哈哈哈哈)
Rust Analyzer 介绍
Rust Analyzer 是由 Rust 社区维护的 Rust 语言 IDE 功能实现,Rust Analyzer 插件搭配 VSCode 可以得到一个现代化的智能 Rust IDE,这或许是目前最流行的 Rust 开发环境。我觉得对于一门新的编程语言,在 VSCode 的强大的编辑器功能上构建 language-specific 的 IDE 功能是兼顾开发成本和用户体验的最佳选择,毕竟从零开发一个 IDE 所需的成本可想而知,而且就算开发出来了短时间内用户体验也比不上经过千锤百炼的 VSCode。
从用户的角度而言,Rust Analyzer 只是 VSCode 插件市场上的一个插件,安装完 Rust 工具链之后再安装这个插件就能得到开箱即用的 IDE 功能。为了达到这个目的,RA 背后做了不少工作。在它的 GitHub 主页 上的 About 介绍上是这么写的:A Rust compiler front-end for IDEs;是的,RA 首先是一个编译器前端,准确的说,它是一个旨在实现 IDE 功能的编译器前端。
这篇文章主要会聚焦在Rust Analyzer 的 IDE 功能实现中的 LSP 部分,LSP 由微软主导,将语言服务器(一个代码分析工具)和语言客户端(VSCode、Sublime Text…)之间的通信进行了标准化,这样一来插件开发者就可以只写一次代码分析程序,然后在多个编辑器中重用。关于 LSP 的更多内容可以查看微软的官方主页。
Rust Analyzer 的客户端(VSCode 插件)代码和语言服务器代码都在同一个仓库中,editors/code 目录下是 VSCode 客户端插件代码,其余均为服务端代码;本文写作时参考的 Rust Analyzer 代码版本为 e1e4626f。
Client 和 Server 的协作方式
Rust Analyzer 客户端和服务端在同一台机器的不同进程中运行。客户端插件激活后会 spawn 一个进程运行服务端。RA 是 C/S 工作模式,不过却是一个 Server 服务一个 Client,这也是我看了代码之后才知道。于是想着验证一下,我在 VSCode 中打开一个新的 Rust Workspace,用 ps 命令查看活动进程后会发现多出一个新的名为 rust-analyzer 的进程。这点倒是出乎我的意料,我还以为以为是一对多呢🤔。不过一对一也合理,这样其中一个 crash 了也不会影响到其他 Client Workspace。
Client 和 Server 这两个进程使用 stdio 进行通信,客户端进程向自己的 stdout 发出的请求服务端会在自己的 stdin 接收到,服务端进程向自己的 stdout 返回响应则会被客户端进程从 stdin 接收。当然,RA 服务端还实现了基于 socket 的 TCP 通信方式,未来不排除有本地 client 连接远程 server 的可能。
Rust Analyzer Client
首先直观地对比一下 Rust Analyzer 客户端和服务端的代码量,客户端 TypeScript 代码不过 5k 行,而服务端 Rust 代码达到了 36w 行。
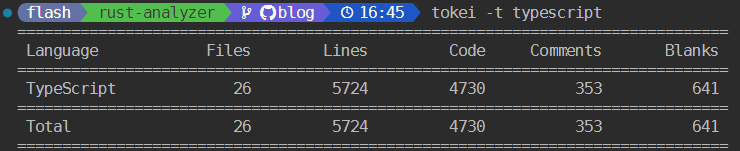
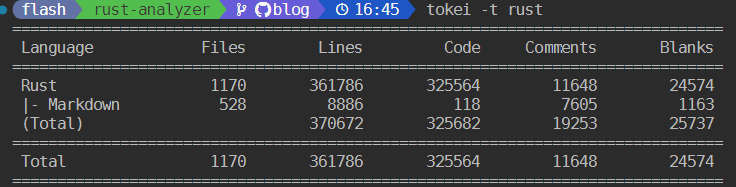
客户端代码量能做到这么少,是因为 Rust Analyzer 在客户端使用了 vscode-languageclient 这个库。vscode-languageclient 是一个 Node.js 库,它提供了一种在 VSCode 插件中实现 LSP 客户端的方式。这个库提供了一些高级的抽象,使得插件可以十分容易地与 LSP 服务器进行交互。客户端代码中只要注册某些处理特定 LSP 事件回调函数,vscode-languageclient 会自动在特定的事件发生后发出对应的 LSP 请求并且调用对应的回调函数处理来自服务端的响应。
比如,当用户在 VS Code 中打开一个 .rs 文件时,这个操作对应一个文件打开事件,vscode-languageclient 则会自动发送 LSP 中的 textDocument/didOpen 请求到服务端,服务端收到会分析打开的这个文件,然后通过一个 textDocument.publishDiagnostics 响应发送给客户端这个文件上的代码诊断,客户端收到这个响应后 vscode-languageclient 会使用默认的处理逻辑处理这个响应(当然也可以 override 为其他逻辑),也就是把这些代码诊断在编辑器中源代码对应的位置展示出来提示用户;最终用户会看到这样的效果:

可视化客户端和服务端的通信过程,大概是这样的效果:

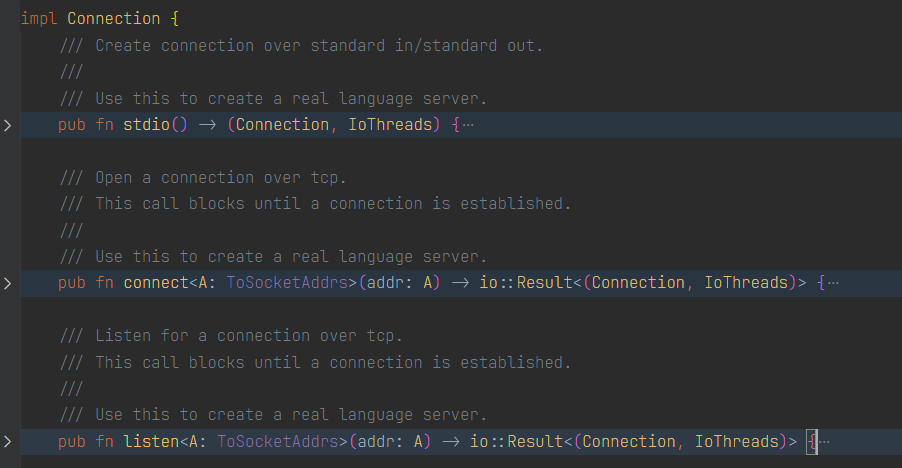
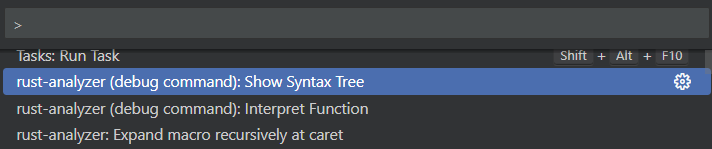
对于 LSP 规范中定义的方法,vscode-languageclient 会自动发送请求和处理响应。对于 LSP 规范中没有定义的方法,插件需要使用 LanguageClient.sendRequest 函数来显式地向服务器发送请求。比如,Rust Analyzer 定义了一些扩展方法(Show Syntax Tree 查看当前文件的抽象语法树,Expand macro 查看宏展开后的代码)来提供一些 LSP 规范中没有的功能。
Rust Analyzer Server
Rust Analyzer 的所有语言服务功能都是在服务端中实现的,为了支持诸如跳转到定义、引用查找、代码诊断等 IDE 功能它实现了一个囊括了 lexering、parsing、IR lowering、type inferencing 等阶段的完整的编译器前端,这也是为什么 RA 服务端代码量达到 36w 行的原因。
服务端的入口点在 run_server,在这里创建一对 crossbeam_channel 的 Sender 和 Receiver 用于收发消息,spawn 出两个线程分别监听 stdin 和 stdout,来自客户端的请求会通过 stdin 传达到 Receiver 中,服务端处理完请求后会将响应通过 Sender 输出到 stdout 从而被客户端接接收。
完成收发消息的准备工作后这一对 crossbeam_channel 会被传递到 main_loop 中,这也是整个服务端的核心。LSP 请求到达 stdin 后,控制流会来到 main_loop 中,根据不同的请求类型(比如要求跳转到定义、提供 inlay hint 等)分派到不同的处理逻辑中。
一个具体的例子
以请求当前光标所在源代码位置的可用 CodeAction 为例,假设当前光标所在位置如下(| 所在位置):
1 | |
此时客户端会发送一个 textDocument/codeAction 类型的 LSP 请求,携带了当前文件以及光标所在具体位置等信息,具体如下:
1 | |
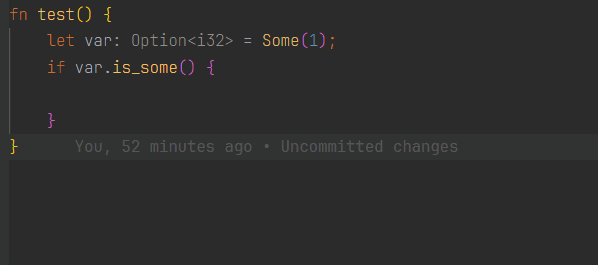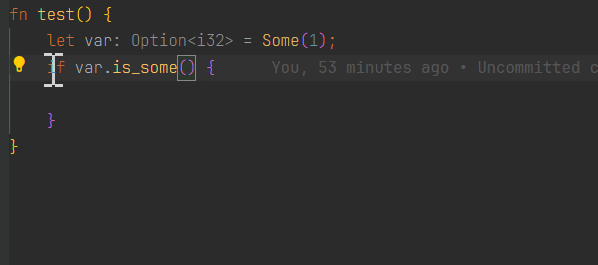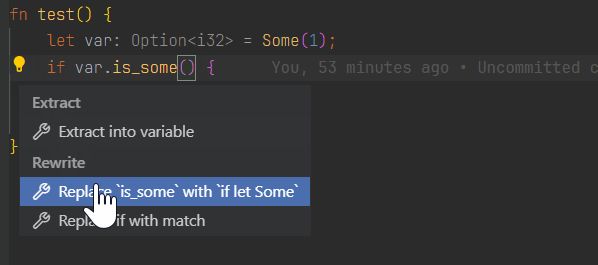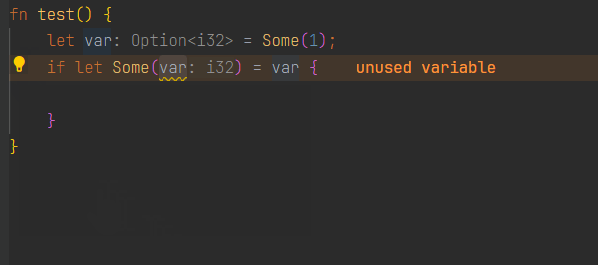
服务端收到后请求并将其序列化为一个内部表示的 lsp_types::CodeActionParams 对象,接着将这个对象代表的请求分派到 handle_code_action 中进行处理,处理过程中发现有两个 CodeAction 适用于光标所在的上下文(为减少篇幅这里我们假设只有两个),一个是将 is_some 写法改为 if let Some,另一个是将 if 写法改为 match 的形式。这两项 CodeAction 分别是在 crates/ide-assists/src/handlers 目录下的 replace_is_method_with_if_let_method.rs(这是我给 RA 提的第一个 PR) 和 replace_if_let_with_match.rs 中基于 AST 进行分析得到的,这个目录下还有许多类似的 .rs 文件,每一个都代表了一个特定上下文中可用的 CodeAction 的分析过程,在处理一个 CodeAction 请求时,其中的每一个文件中的逻辑都会被执行,如果这个 CodeAction 适用于当前上下文则会返回 Some 否则则是 None。
 对于前面举的例子中的两个可用 CodeAction,服务端会返回这样的响应,其中的
对于前面举的例子中的两个可用 CodeAction,服务端会返回这样的响应,其中的 title 字段也就是我们点击了💡后所看到的内容。
1 | |
当我们决定应用其中一项时(假设是 Replace is_some with if let Some),点击对应的文字,此时客户端会发出一个 codeAction/resolve 请求,向服务端请求应用这个 CodeAction 后源代码会如何被改写,
1 | |
服务端根据请求中的信息进行计算分析后,返回给客户端具体的响应,其中的 newText 和 range 字段告诉客户端把 range 范围中的旧代码替换为 newText 表示的内容。
1 | |
一个完整的请求响应过程至此结束,类似的过程在用户在编辑器中写代码,移动鼠标悬浮,各种点击查看等的过程中时刻发生着。
参考
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!